In this article I will show you how to migrate a site created with an old, and nowadays deprecated content management system to a contemporary CMS, using web automation tools – that is grabbing a site’s content by walking through it with bots imitating human visitors, and uploading it to the new site similarly, by acting just like a human editor.
More than a decade ago I started to build a very successful website with a simple yet powerful Zope-based Wiki engine called Zwiki. As both Wikis (with the one notable exception of Wikipedia) and Zope usage has been in decline for many years, I haven’t actively developed that site anymore, but as I did not want to lose its content, I decided to migrate it to WordPress.
Step #1: Scraping a Zwiki site
Getting structured content from a wiki
When moving a site, the first challenge is to download the website’s content in a structured format. As we are talking about a wiki-type site, there is a strong emphasis on the word: structured, as the basic philosophy of the wikis consists of adding content to one single page body field, and using certain kind of formatting notations inside of that one big content field to display the information in a format which resembles some structure. Zwiki, for instance, has a handy function which allows commenting and following others’ comment on any wiki page, but all the comments are to be added to the very same field where the actual page content is stored, therefore I had to find in the pages’ text where each comment begins, and store them separately from the content.
Dealing with the special content markup
Yet another challenge was that Zwiki, just as many of its counterparts, uses a specific, simpler-than-HTML kind of markup code, which cannot be recognised by any contemporary content management system, so I could not rely on the content I could get by opening all the pages for editing, so I had to scrape the public web pages, where the special markup is already interpreted and translated to ordinary HTML.
Imitating human visitors with web automation tools
As I have experience working with a few web scraping/web automation software my obvious choice was to scrape the Zwiki site as if a human visitor would click through each and every link on the page and download its content. This way you are not limited by the export/import formats a certain CMS would offer when it comes to acquiring and uploading content, but you can get whatever part of the content you want, and process them with whatever regular expressions you want and log the results in any format. If a human visitor can walk through the entire site, you can grab all the information.
The logic behind the scraper script
Wiki-based content management systems tend to have a feature which greatly simplifies the content scraping process: they usually have a wiki contents page where all the pages of the wiki are listed. Therefore it seemed to be a very easy task to get all the content I needed to move: just open the contents page, scrape all the links, go through the list of them and visit, download and post-process each one. As an output, I have generated a .csv file where the page hierarchy, that is all the parent pages has been logged, another .csv file where the actual content of each page has been logged with a few pieces of key information such as title, URL or last modified date. This last piece of information could be obtained by visiting each wiki page’s history sub page and reading the dates of previous changes listed there. The third file had every comment in a separate row, extracted by regular expressions from the page content. I have also generated another file with the raw content for debugging purposes. It records the page content plus the comments in their original format so that if something went wrong with the processing of the comments, the original source could be at hand.
Putting it all together with UBot Studio
As the whole process didn’t seem to be too difficult, I opted for using Ubot Studio for downloading and structuring the site’s content. It is marketed as an automation tool for internet marketers, but to be honest its main purpose was once to scrape and spam websites by link submissions, comments, etc. But nevertheless it can be used for various web automation purposes, and one of its key function that the Bots I create can be compiled in a .exe format, which can be run on any Windows computer, without having to buy the software itself. I would not publish this executable as I don’t want anyone to play around with scraping Zwiki sites, thus putting an unnecessary load on their servers, but feel free to contact me by commenting this page or dropping me a mail (kedves /at/ oldalgazda /dot/ hu) if you need that .exe file to migrate your Zwiki site as well.
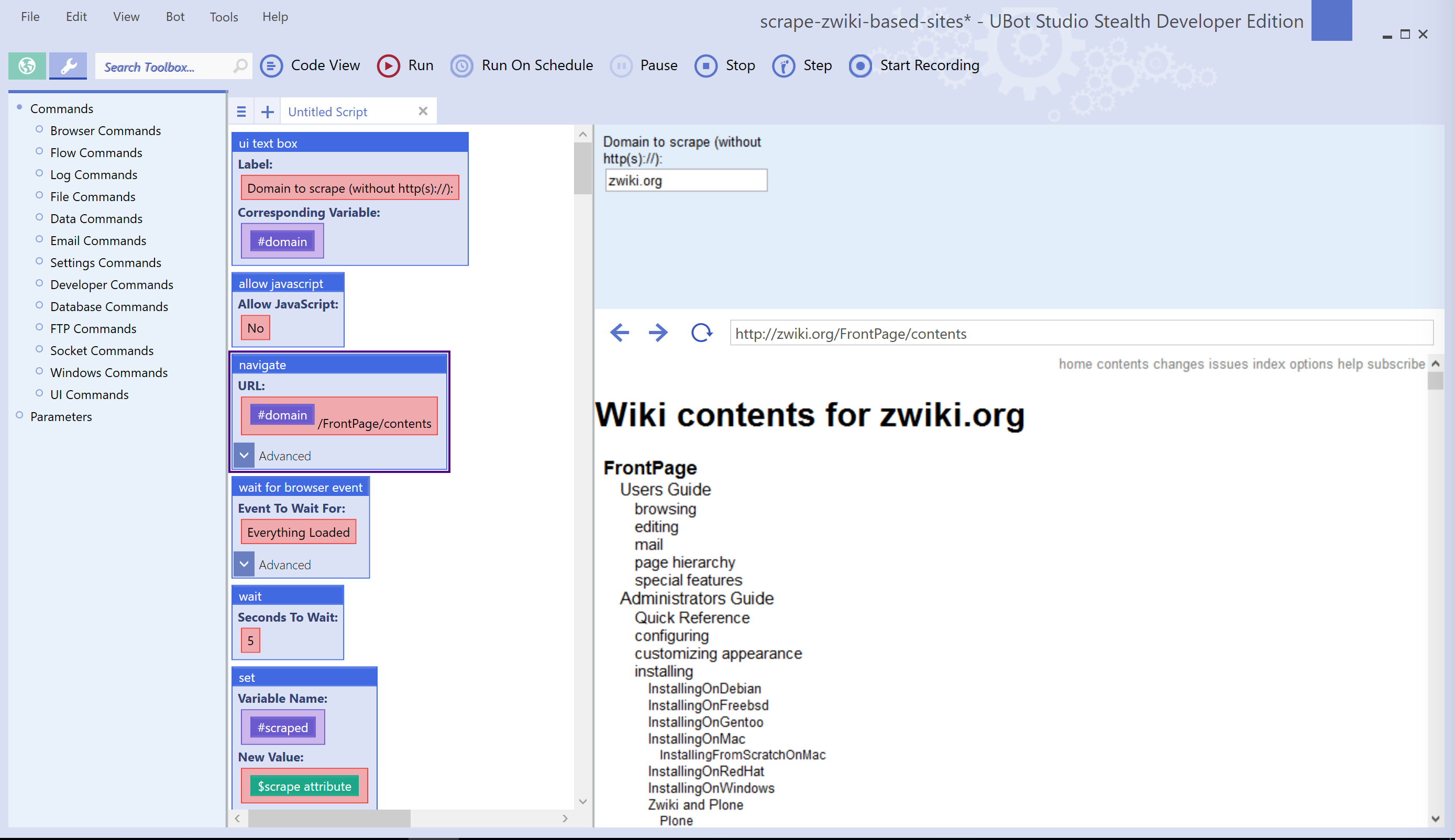
Another interesting feature of Ubot is that although its primary interface is a visual programming UI, you can still switch to code view, where you can edit the script as if it was coded in an ”ordinary” programming language. The Zwiki scraper script, for instance, looks like this below in code view. If you have some patience, you can go through the script and understand what each step did, and see which regular expressions I used when structuring the data:
ui text box("Domain to scrape (without http(s)://):",#domain)
allow javascript("No")
navigate("{#domain}/FrontPage/contents","Wait")
wait for browser event("Everything Loaded","")
wait(5)
set(#scraped,$scrape attribute(<class="formcontent">,"innerhtml"),"Global")
add list to list(%pageurls,$find regular expression(#scraped,"(?<=href=\")[^\"]+"),"Delete","Global")
loop($list total(%pageurls)) {
set(#pageurl,$list item(%pageurls,1),"Global")
navigate(#pageurl,"Wait")
wait for browser event("Everything Loaded","")
wait(5)
set(#content,$scrape attribute(<class="content">,"innerhtml"),"Global")
set(#content,$replace regular expression(#content,"<a\\ class=\"new\\ .+?(?=</a>)</a>","<!-- no wikipage yet -->"),"Global")
set(#content,$replace(#content,$new line,$nothing),"Global")
set(#content,$replace regular expression(#content,"\\t"," "),"Global")
set(#contentonly,$replace regular expression(#content,"<p><div\\ class=\"subtopics\"><a\\ name=\"subtopics\">.+",$nothing),"Global")
set(#contentonly,$replace regular expression(#contentonly,"<p><a name=\"comments\">.+",$nothing),"Global")
set(#contentonly,$replace regular expression(#contentonly,"<a name=\"bottom\">.+",$nothing),"Global")
add list to list(%parents,$scrape attribute(<class="outline expandable">,"innertext"),"Delete","Global")
set(#parentlist,$list item(%parents,0),"Global")
clear list(%parents)
add list to list(%parents,$list from text(#parentlist,$new line),"Delete","Global")
set(#parentlist,$replace(#parentlist,$new line,";"),"Global")
set(#posttitle,$list item(%parents,$eval($subtract($list total(%parents),1))),"Global")
set(#posttitle,$replace(#posttitle," ...",$nothing),"Global")
if($comparison($list total(%parents),"> Greater than",1)) {
then {
set(#parent,$list item(%parents,$eval($subtract($list total(%parents),2))),"Global")
}
else {
set(#parent,$nothing,"Global")
}
}
append to file("{$special folder("Desktop")}\\{#domain}-page-hierarchy.csv","{#pageurl} {#posttitle} {#parent} {#parentlist} {$new line}","End")
clear list(%parents)
add list to list(%comments,$find regular expression(#content,"<p><a[^>]+name=\"msg.+?(?=<p><a[^>]+name=\"msg.+)"),"Delete","Global")
loop($list total(%comments)) {
set(#comment,$list item(%comments,0),"Global")
set(#date,$find regular expression(#comment,"(?<=name=\"msg)[^@]+"),"Global")
set(#title,$find regular expression(#comment,"(?<=<b>).+?(?=</b>\\ --)"),"Global")
set(#title,$replace regular expression(#title,"<[^>]+>",$nothing),"Global")
set(#author,$find regular expression(#comment,"(?<=</b>\\ --).+?(?=<a\\ href=\"{#pageurl})"),"Global")
set(#author,$replace regular expression(#author,"<[^>]+>",$nothing),"Global")
set(#author,$replace regular expression(#author,",\\ *$",$nothing),"Global")
set(#comment,$find regular expression(#comment,"(?<=<br(|\\ /)>).+"),"Global")
set(#comment,"<p>{#comment}","Global")
set(#comment,$replace regular expression(#comment,"\\t"," "),"Global")
append to file("{$special folder("Desktop")}\\{#domain}-page-comments.csv"," {#pageurl} {#date} {#title} {#author} {#comment} {$new line}","End")
remove from list(%comments,0)
}
navigate("{#pageurl}/history","Wait")
wait for browser event("Everything Loaded","")
wait(5)
scrape table(<outerhtml=w"<table>*">,&edithistory)
set(#lastedited,$table cell(&edithistory,0,4),"Global")
clear table(&edithistory)
append to file("{$special folder("Desktop")}\\{#domain}-page-content-raw.csv","{#pageurl} {#lastedited} {#content} {$new line}","End")
append to file("{$special folder("Desktop")}\\{#domain}-page-content-only.csv","{#pageurl} {#posttitle} {#lastedited} {#contentonly} {$new line}","End")
remove from list(%pageurls,0)
}
Step #2 Uploading the content to WordPress
Now that I have all the necessary data downloaded to .csv files in a structured format, I needed to create other scripts to upload the content to a WordPress site. Here I opted for the same technique, that is imitating a human visitor, which hits the ”Create a new page” button each and every time, and fills all the edit fields with the data grabbed from the downloaded .csv files. More details about this part can be read here: From Plone to WordPress — Migrating a site with web automation tools